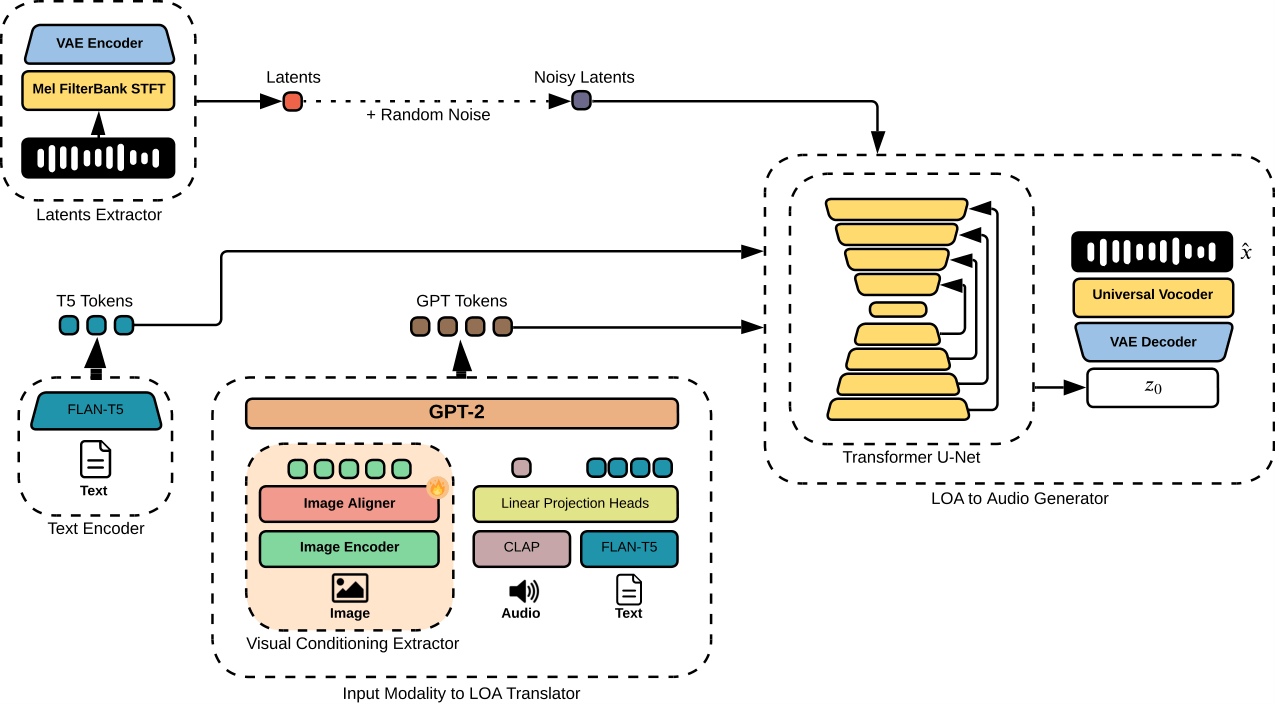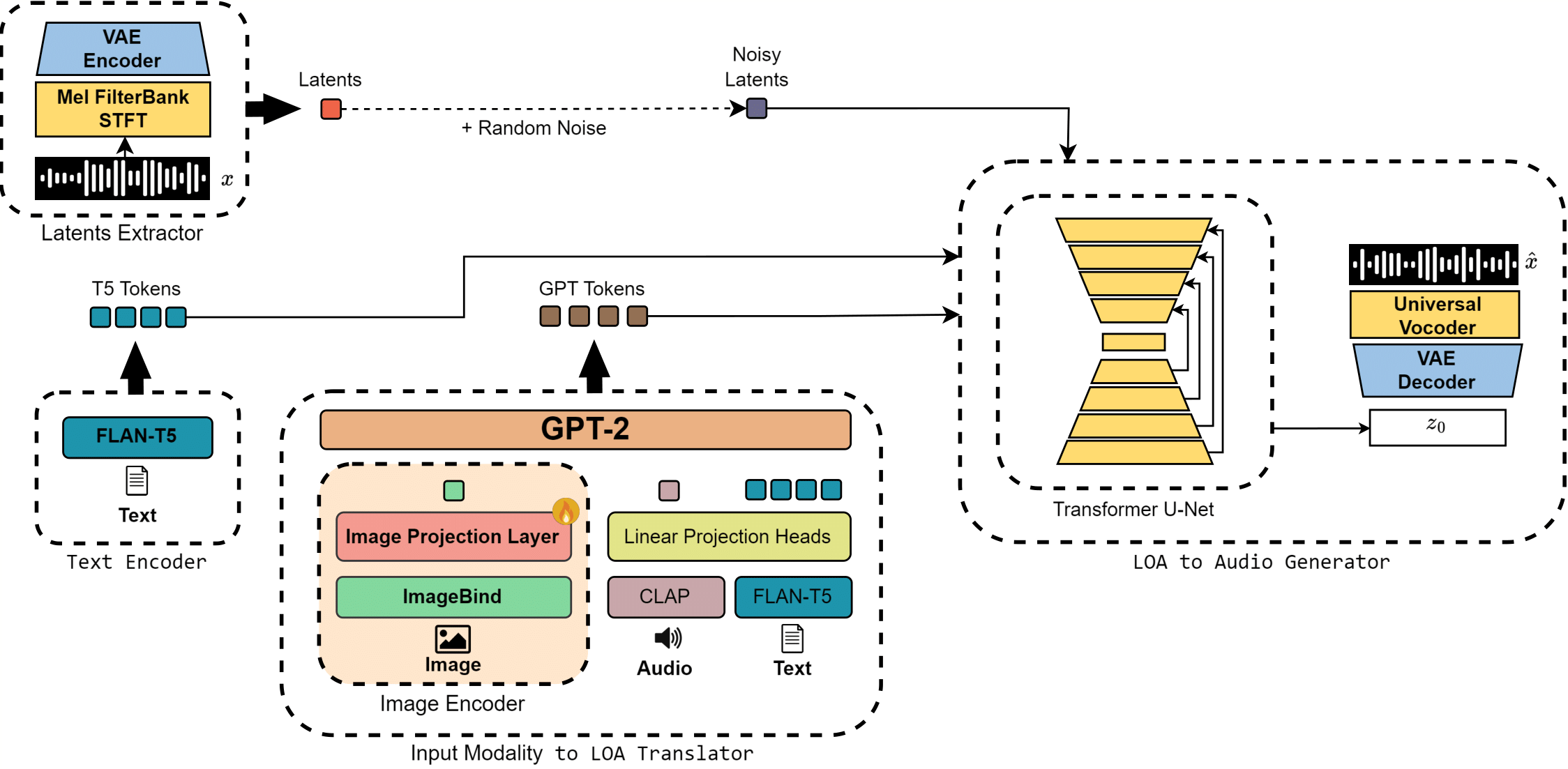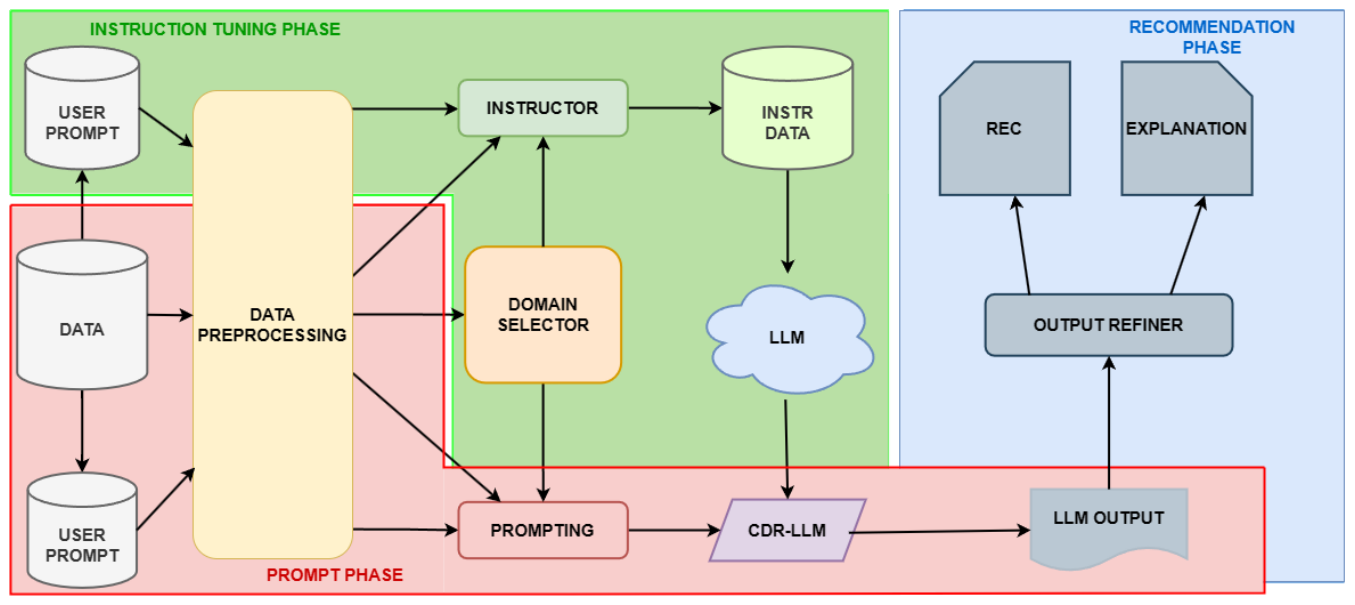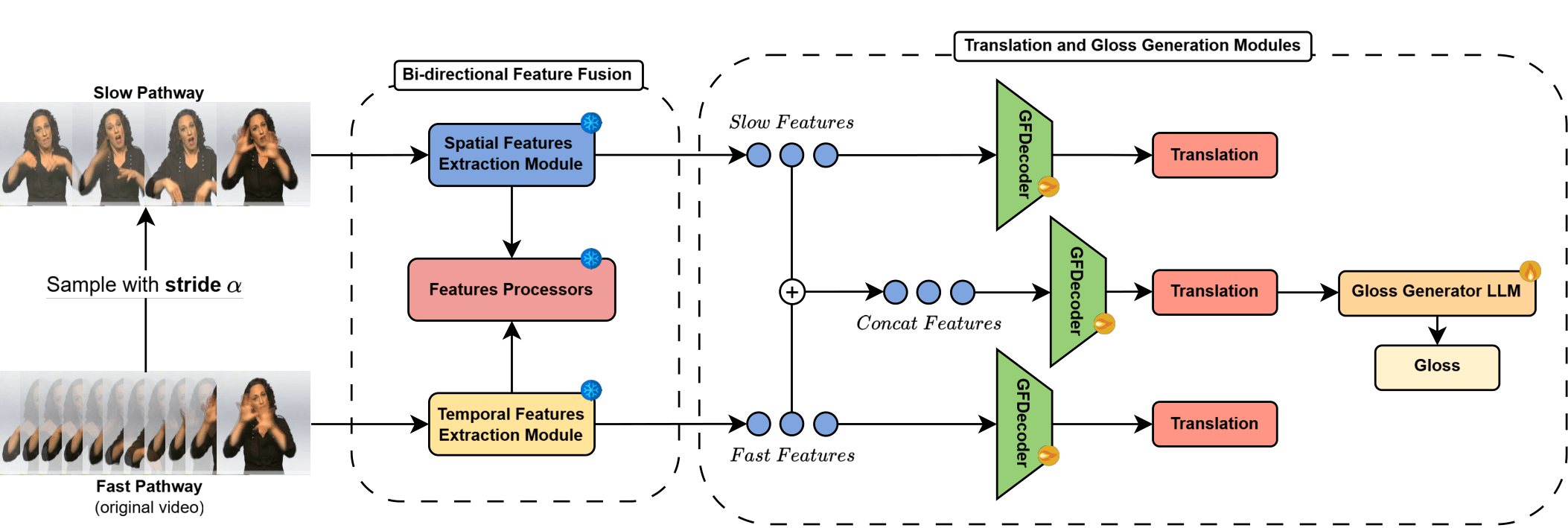
🖐🏻 Handscribe: A Gloss-Free Framework for Sign Language Translation and Gloss Sequence Generation 🤌🏻
Emanuele Colonna and Ivan Rinaldi and David Landi and Gennaro Vessio and Giovanna Castellano
Sign language translation systems traditionally rely on intermediate gloss representations to bridge the gap between visual input and written language output. However, manual gloss annotation is costl...